

A perda de dados é um dos problemas mais frustrantes que qualquer usuário pode enfrentar. Seja por exclusão acidental, formatação indevida ou falha no dispositivo. Felizmente, na maioria dos casos, esses dados não são perdidos permanentemente. Neste artigo, vamos explorar em profundidade como funciona o processo de recuperação de dados em pendrives e, mais importante, como você pode desenvolver sua própria ferramenta de recuperação utilizando a linguagem de programação C.
Sistema de arquivos
Um sistema de arquivos é o mecanismo lógico que o sistema operacional utiliza para organizar, armazenar, acessar e gerenciar os dados dentro de um dispositivo de armazenamento, como HDs, SSDs, pendrives ou cartões de memória. Ele define como os dados serão distribuídos fisicamente no disco e como serão recuperados depois, funcionando como uma espécie de “índice” que permite ao sistema saber onde cada arquivo começa, onde termina, qual é seu nome, seu tamanho e suas propriedades.
Sem um sistema de arquivos, o dispositivo seria apenas um espaço bruto de bits, sem qualquer estrutura compreensível. O sistema operacional não conseguiria distinguir um arquivo de outro, nem localizar informações específicas. Portanto, o sistema de arquivos é responsável por transformar o armazenamento físico em algo utilizável, criando diretórios, controlando o espaço livre, registrando onde cada parte dos arquivos está gravada e garantindo que as operações de leitura e escrita aconteçam corretamente.
O FAT32 é um tipo específico de sistema de arquivos desenvolvido pela Microsoft como evolução de versões anteriores chamadas FAT12 e FAT16. O nome significa File Allocation Table 32 (Tabela de Alocação de Arquivos de 32 bits) e descreve a principal característica desse sistema: ele utiliza uma tabela para controlar a localização dos dados no disco.
Como o FAT32 organiza os dados
Todo dispositivo de armazenamento que contempla o sistema de arquivos FAT32 – geralmente todo pendrive FAT32 como sistema de arquivos – é formado por setores de 512 bytes, cuja união adjacente forma os chamados blocos ou clusters. Pode-se ter blocos formados por diferentes números de setores, porém é usual a utilização de 8 setores adjacentes. É importante ressaltar que um cluster só pode armazenar um único arquivo no dispositivo e como o FAT32 pode trabalhar com clusters de 4KB, o desperdício em disco foi grandemente reduzido se comparado com o sistema FAT16.
Quando um dispositivo de armazenamento passa pela formatação lógica completa usando o sistema de arquivos FAT32, os setores e blocos que formam este dispositivo assumem uma funcionalidade específica que viabiliza toda a estrutura do FAT32.
O setor MBR
O setor chamado de Master Boot Record (MBR) conta com 512 bytes, cujos 446 primeiros, representam a área de boot do sistema, seguida por 4 partições de 16 bytes cada e pelos bytes 0x55 e 0xAA, que indicam o final do setor.
É importante ressaltar que, para desenvolver um undelete, não é preciso alterar nenhuma parte relacionada ao MBR, pois é importante a integridade deste setor para que o sistema operacional possa gerenciar corretamente o dispositivo de armazenamento usado.Vale lembrar que em dispositivos como pen drives, não existe o setor Master Boot Record, pois eles já começam no setor FAT Volume ID.

Os demais setores
Após o Master Boot Record, tem-se alguns setores conhecidos como reserved sectors (setores reservados) que possuem informações importantes para o sistema operacional e devem ser preservados durante a realização do programa de undelete.
A quantidade de setores reservados pode ser adquirida por meio dos metadados localizados no FAT Volume ID. Veja abaixo como é a estrutura do FAT Volume ID.
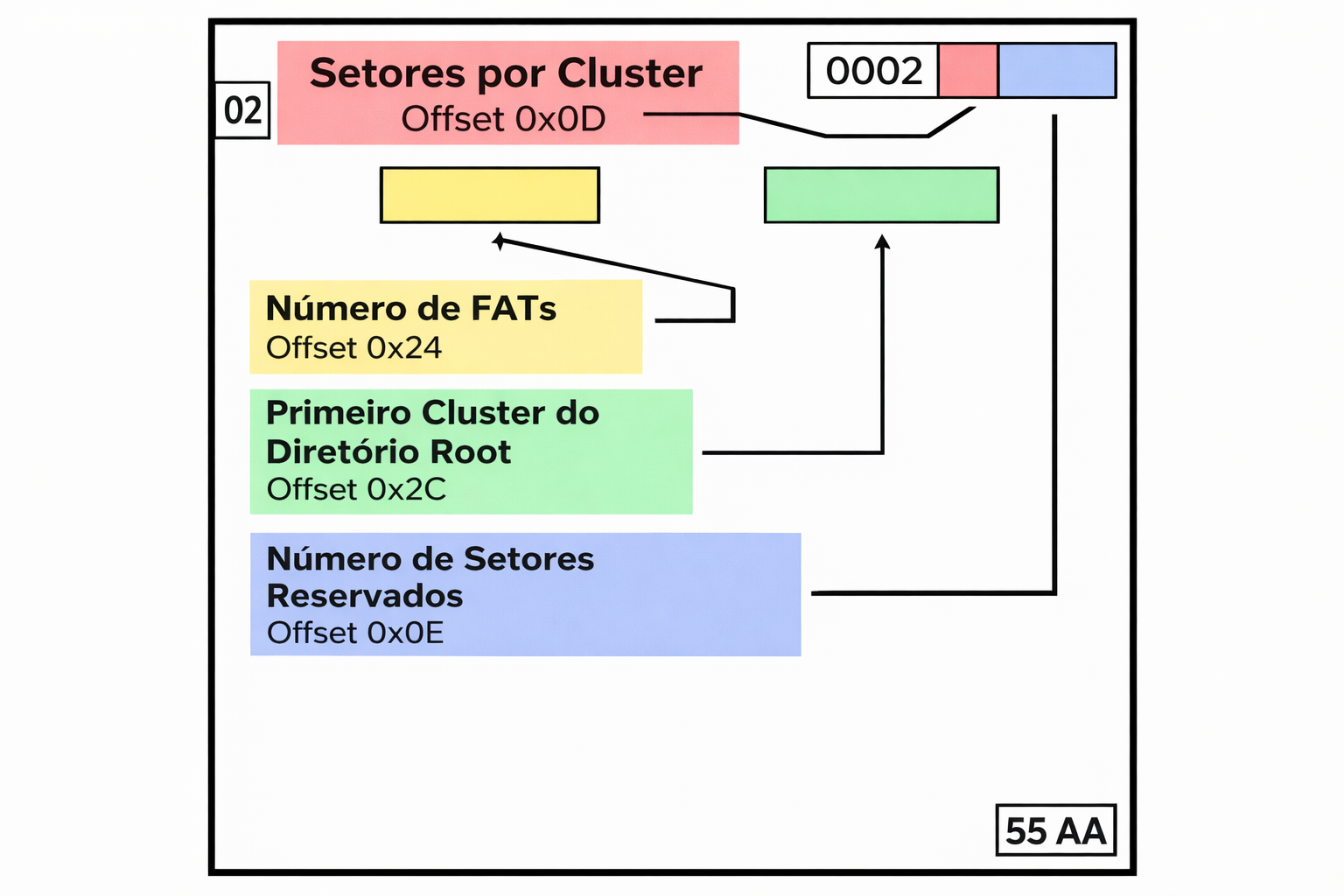
A partir de então, chega-se à primeira cópia da FAT, cuja extensão pode ser determinada com o auxílio dos metadados disponíveis no FAT Volume ID e que guarda informações importantes acerca dos arquivos que o dispositivo possui. Conjuntos de 4 bytes consecutivos na FAT representam entradas para os clusters. O número definido pelos bytes (considerando a representação little endian) corresponde ao índice do próximo cluster utilizado pelo arquivo contido no presente cluster, a não ser que este seja o cluster final utilizado pelo arquivo, neste caso a entrada conterá os bytes “FF FF FF 0F”. A FAT, então, implementa para cada arquivo uma lista encadeada de clusters.
Se o conjunto de bytes corresponder o número zero, pode-se afirmar que o cluster representado por essa entrada está disponível. Existem outros valores reservados além de “00 00 00 00” e “FF FF FF 0F” porém não são necessários para o desenvolvimento de um undelete.

A imagem e a tabela abaixo nos ajudaram a dar os primeiros passos para entender a estrutura do sistema de arquivos FAT32. É possível extrair informações importantes acerca do número de bytes por setor, número de FAT’s, setores por cluster, entre outros e também seus respectivos offsets. Com isso, foi possível entender como chegar nos locais que eram necessários para a realização do undelete
Adiante, tem-se a área denominada de root directory (diretório raiz) que representa a entrada da região de dados do sistema de arquivos FAT32. O diretório raiz é de grande importância para o processo de undelete, pois é nele que residem os bytes que nos indicam que determinado arquivo foi realmente deletado. Portanto, é preciso alterar esses bytes de modo a inserir os valores originais para que o arquivo passe a ser visto novamente como um arquivo presente no dispositivo.
Após essa área, temos finalmente a região de dados, onde os arquivos estarão de fato localizados, ocupando espaços em seus clusters.
O Undelete
Podemos definir Undelete como um processo capaz de recuperar arquivos apagados, e isso é possível porque quando apagamos um arquivo ele ainda permanece na memória e o sistema operacional evita sobrescrever os dados do arquivo que foi apagado, de modo que seja possível sua recuperação mesmo muito tempo após a deleção. Entretanto, se o sistema operacional precisar daquela região para alocar um novo arquivo, então os dados do arquivo anterior se perdem e o processo de recuperação já não é mais possível.
Esse processo consiste em achar bytes especiais no diretório raiz, que indicam que determinado arquivo foi deletado e alterá-los de modo a incluir os bytes originais do arquivo. Após isso, é preciso acessar as duas cópias da Fat para que sejam realizadas modificações em alguns bytes de modo que arquivo seja realmente recuperado. Se este possuir apenas 1 cluster de armazenamento, o que precisa ser feito é apenas alterar os 4 bytes referentes àquele cluster em ambas as cópias da Fat, trocando os bytes “0F 00 00 00 00 00 00 00 00” por “0F 00 00 00 00 FF FF FF 0F”.
Passo a passo da implementação em C
Disposto de todo o conhecimento abordado até aqui, será mostrado agora como foi feita a implementação passo a passo.
Implementando a função main
O primeiro passo inicia-se na main onde é criado um array do tipo char que irá receber do usuário o nome da partição de seu pen drive, para que posteriormente seja concatenado com o “/dev” na operação de open do dispositivo. Se a operação open retornar um valor menor que zero, é mostrada uma mensagem de erro para o usuário, o que pode ser devido ao nome incorreto do dispositivo ou a não utilização do comando “sudo” para adquirir a permissão de administrador que se faz necessária para a operação de undelete.
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<fcntl.h>
#include<stdlib.h>
#define BUFFER_SZ 1 << 20
int bytes_per_sector;
int sectors_per_cluster;
int reserved_sectors;
int num_of_fats;
int sectors_per_fat;
int root_cluster;
int root_directory_sector;
int cluster_bytes;
int files_selected_amount;
char *file_list[105];
int usb_file;
unsigned char buffer[BUFFER_SZ];
int main (){
char device_filename[10];
printf("Digite o nome do seu dispositivo: ");
scanf("%s", device_filename);
char device_path[20];
sprintf(device_path, "/dev/%s", device_filename);
usb_file = open(device_path, O_RDWR);
if(usb_file < 0){
printf("FATAL ERROR\n");
return -1;
}
//continua...
Após isso, é executado um comando “read” para que seja lido e armazenado os 512 bytes do
FAT Volume ID, de modo que possa ser possível adquirir informações a respeito de vários
aspectos da estrutura de nosso dispositivo como: número de setores reservados, número de
setores por cluster, número de setores por FAT, entre outros, como mostra o bloco de código abaixo.
//...
read(usb_file, buffer, 512);
bytes_per_sector = buffer[0x0B] + (buffer[0x0C] * 256); //quantidade de bytes por setor
sectors_per_cluster = buffer[0x0D]; //quantidade de setores por cluster
reserved_sectors = buffer[0x0E] + (buffer[0x0F] * 256); //quantidade de setores reservados
num_of_fats = buffer[0x10]; //número de FATs
sectors_per_fat = *((unsigned int *)(buffer+0x24)); //quantidade de setores por FAT
root_cluster = *((unsigned int *)(buffer+0x2C)); //índice do root cluster
root_directory_sector = reserved_sectors + (num_of_fats * sectors_per_fat); //quantidade de setores antes do root directory
cluster_bytes = sectors_per_cluster * bytes_per_sector; //quantidade de bytes por cluster
//continua...
Posteriormente, é realizado uma operação “lseek” para se chegar no diretório raiz e uma operação “read” para que seus bytes sejam lidos e armazenados. Então, seus bytes são percorridos de modo que, se um byte do tipo “E5” for detectado, um ponteiro char de 32 bytes é criado e alocado e guardará os proxímos 32 bytes.
A partir de então, alguns comandos condicionais são executados para que sabermos se tudo se comporta conforme é necessário, utilizando a função “isAtFileList”. Por exemplo, se o usuário escolher a opção 2 ou 3, esses comandos condicionais irão dizer se os arquivos passados realmente foram digitados corretamente.
//...
lseek(usb_file, root_directory_sector * bytes_per_sector, SEEK_SET);
read(usb_file, buffer, cluster_bytes);
int files_recovered = 0;
for (int i=0; i<cluster_bytes; i += 32) {
if(buffer[i] == 0xE5) {
unsigned char *file_entry;
file_entry = (unsigned char *)malloc(sizeof(unsigned char)*32);
for (int j=i+32; j<i+64; j++) file_entry[j-(i+32)] = buffer[j];
if(!checkRecovery(file_entry)){
i += 32;
continue ;
}
//continua...
Implementando a função que verifica a recuperação
A função “checkRecovery” é chamada para que ela informe se aquele arquivo é passível de recuperação. Com o auxílio de outras duas (getFileFirstCluster e getFileSize), basicamente ela verifica a quantidade de clusters que existem antes do primeiro cluster que contém o arquivo, fazendo operações para conversão de little-endian para big-endian, verifica a quantidade de bytes deste arquivo, e então verifica se os bytes presentes em ambas as cópias da FAT são zeros. Se os bytes forem todos zeros, isso significa que o arquivo pode passar
pelo processo de undelete, começando pela recuperação das FAT’s.
int checkRecovery(unsigned char* file_entry) {
int first_cluster = getFileFirstCluster(file_entry); //quantidade de clusters antes do primeiro cluster que contém o arquivo
int sz = getFileSize(file_entry); //quantidade de bytes do arquivo
int used_clusters = (sz / cluster_bytes); //baseado no tamanho de arquivos, este valor representa a quantidade de clusters que o arquivo deve ocupar
if (sz % cluster_bytes != 0) used_clusters++;
unsigned char aux_buffer[4];
lseek(usb_file, reserved_sectors * bytes_per_sector + first_cluster * 4, SEEK_SET);
for (int i=0; i<used_clusters; i++) {
read(usb_file, aux_buffer, 4);
for (int j=0; j<4; j++) {
if((int)aux_buffer[j] != 0) {
return 0;
}
}
}
lseek(usb_file, (reserved_sectors + sectors_per_fat) * bytes_per_sector + first_cluster * 4, SEEK_SET);
for (int i=0; i<used_clusters; i++) {
read(usb_file, aux_buffer, 4);
for (int j=0; j<4; j++) {
if((int)aux_buffer[j] != 0) {
return 0;
}
}
}
return 1;
}
Implementando a função de conversão
Por meio de manipulações e conversões little-endian para big-endian, a função “getFirstCluster” retorna a quantidade de clusters que existem antes do primeiro cluster ocupado pelo arquivo.
unsigned int getFileFirstCluster(unsigned char* file_entry) {
unsigned int hi = (unsigned int)file_entry[20] + ((unsigned int)file_entry[21] * 256);
unsigned int lo = (unsigned int)file_entry[26] + ((unsigned int)file_entry[27] * 256);
return lo + (hi * 256 * 256);
}
Implementando da função que retorna a quantidade de bytes
A função “getFileSize” retorna a quantidade de bytes de determinado arquivo. Isso porque, na estrutura do diretório raiz do FAT32, os 4 últimos bytes dos 32 bytes que representam o arquivo, dizem respeito ao tamanho desde aquivo. Acontece que, os valores nesses bytes no formato little endian e precisamos passa-los para o formato big endian, por isso fazemos as multiplicações por 256.
unsigned int getFileSize(unsigned char* file_entry) {
unsigned int sz = (unsigned int)file_entry[28] + ((unsigned int)file_entry[29] * 256) + ((unsigned int)file_entry[30] * 256*256) + ((unsigned int)file_entry[31] * 256*256*256);
return sz;
}
Continuando a implementação da main
Voltando para a “main”, teremos a chamada da função “recoverFATs”.
//...
recoverFATs(file_entry);
//continua...
Implementando a função de recuperação de arquivo
Esta função, analisará os cluters usados pelos arquivos nas FAT’s e usará a função “write” para sobrescrever alguns bytes importantes. Após atingir o cluster final do arquivo, seus 4 bytes serão substituídos por “FF FF FF 0F” de modo que o arquivo passe a ser tratado como existente novamente. Isso é feito nas duas cópias da FAT do sistema de arquivos.
void recoverFATs(unsigned char *file_entry) {
//Recover file at FAT#1
int first_cluster = getFileFirstCluster(file_entry);
int sz = getFileSize(file_entry);
int used_clusters = (sz / cluster_bytes);
if (sz % cluster_bytes != 0) used_clusters++;
lseek(usb_file, reserved_sectors * bytes_per_sector + first_cluster * 4, SEEK_SET);
unsigned char new_clusters_entry[4];
for (int cluster = first_cluster; cluster < used_clusters-1; cluster++) {
unsigned int val = cluster + 1;
for (int j=0; j<4; j++) {
new_clusters_entry[j] = val & ((1 << 8)-1);
val >>= 8;
}
write(usb_file, new_clusters_entry, 4);
}
new_clusters_entry[0] = new_clusters_entry[1] = new_clusters_entry[2] = 0xFF;
new_clusters_entry[3] = 0x0F;
write(usb_file, new_clusters_entry, 4);
//Recover file at FAT#2
lseek(usb_file, (reserved_sectors + sectors_per_fat) * bytes_per_sector + first_cluster * 4, SEEK_SET);
for (int cluster = first_cluster; cluster < used_clusters-1; cluster++) {
unsigned int val = cluster + 1;
for (int j=0; j<4; j++) {
new_clusters_entry[j] = val & ((1 << 8)-1);
val >>= 8;
}
write(usb_file, new_clusters_entry, 4);
}
new_clusters_entry[0] = new_clusters_entry[1] = new_clusters_entry[2] = 0xFF;
new_clusters_entry[3] = 0x0F;
write(usb_file, new_clusters_entry, 4);
}
Finalmente, voltamos por último para a função main do programa para trocarmos aqueles 2 bytes “E5” presentes no diretório raiz. O primeiro desses bytes é substituído pela primeira letra que compõe o nome do arquivo, porém em sua versão maiúscula (para isso usamos a função “toUpper”) e o segundo byte é trocado simplesmente pelo caractere “A”.
Também é acrescido 1 na variável que conta quantos arquivos foram recuperados. Como ação final, executamos um “lseek” para a região do diretório raiz e usamos a função “write” para que os bytes sejam sobrescritos no dispositivo. Lembrando que todo esse processo é repetido até que o programa alcance o final do diretório raiz, sempre indo de 32 em 32 bytes pois esse é tamanho usado por cada arquivo no diretório raiz. Por fim, fechamos o dispositivo e mostramos na tela a quantidade de arquivos recuperados.
Finalizando a implementação da função main
//...
unsigned char first_char = buffer[i+1];
buffer[i+32] = toUpper(first_char);
buffer[i] = 'A';
files_recovered++;
i += 32;
}
}
lseek(usb_file, root_directory_sector * bytes_per_sector, SEEK_SET);
write(usb_file, buffer, cluster_bytes);
close(usb_file);
printf("Recovered a total of %d files\n", files_recovered);
return 0;
}
Implementando a função para deixar letras maiúsculas
A função toUpper padroniza os caracteres de modo a deixá-los maiúsculos
unsigned char toUpper(unsigned char x) {
if(x >= 'a' && x <= 'z') {
x += ('A' - 'a');
}
return x;
}
Execução do programa
Para se testar o programa, foi usado um pendrive com três arquivos apagados e a ideia é que quando o código for executado, esses arquivos sejam recuperados.

A partir de então, podemos executar o código como mostra a imagem abaixo.
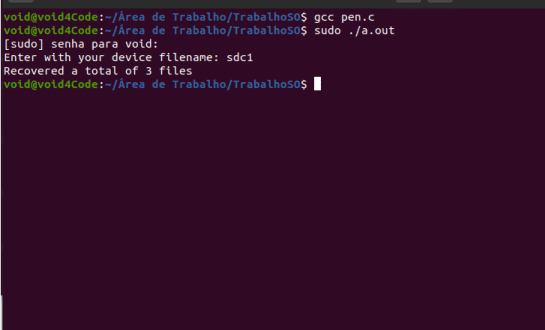
Vale lembrar que para encontrar o nome do seu dispositivo você pode usar o comando abaixo
sudo fdisk -l
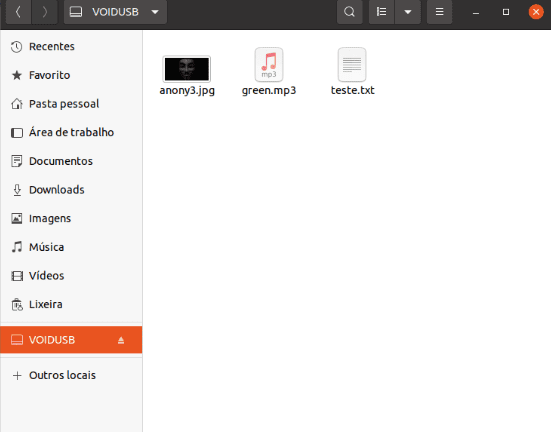
Após exeuctar, se verificarmos os arquivos no pendrive veremos que os três arquivos que eu mencionei que estavam no pendrive apareceram novamente.
Curtiu mas não sabe onde começar ? Comece baixando o codeBlocks para o Linux.


