

Sua aplicação está em produção, os usuários começam a reclamar de lentidão e ninguém consegue explicar por que o servidor de repente entra em colapso nos horários de pico. Neste artigo, você vai entender como um conceito da Teoria da Filas é capaz de solucionar esse problema e como implementá-lo em Python para extrair métricas valiosas sobre o comportamento do servidor antes que os problemas aconteçam.
Sistema de filas
Todo servidor web, banco de dados, fila de mensagens ou qualquer serviço que processa requisições pode ser abstraído como um sistema de filas: chegam pedidos, eles esperam por um recurso disponível, são atendidos e saem.
A Teoria das Filas é o ramo da matemática e da pesquisa operacional que estuda exatamente esses sistemas. Ela permite responder perguntas como:
- Qual é o tempo médio que uma requisição espera na fila?
- Quantas requisições estarão acumuladas no servidor em média?
- Qual é a probabilidade de o servidor estar ocioso?
- A partir de qual taxa de chegada meu servidor entra em colapso?
Essas perguntas têm respostas analíticas, isto é, você não precisa simular milhões de requisições para obtê-las. Com alguns parâmetros do seu servidor, as fórmulas da teoria das filas entregam as respostas diretamente. O modelo mais simples e amplamente utilizado é o M/M/1, que serve como ponto de partida para a análise de praticamente qualquer servidor.
O que é uma fila M/M/1 ?
Uma fila M/M/1 é um modelo matemático da teoria das filas usado para analisar sistemas onde clientes chegam, esperam em uma fila e são atendidos por um único servidor. Esse modelo é muito usado em áreas como redes de computadores, sistemas operacionais, telecomunicações e atendimento ao cliente para prever tempo de espera, tamanho da fila e utilização do servidor.
A notação M/M/1 vem da Notação de Kendall, um sistema padronizado para descrever filas com três campos A/B/c, onde:
- A – Distribuição dos intervalos entre chegadas
- B – Distribuição dos tempos de serviço
- c – Número de servidores
Com base nessa notação a fila M/M/1 segue uma estrutura semelhante, veja:
- Primeiro M: Significa que as chegadas seguem um processo de Poisson, ou seja, os intervalos entre chegadas seguem uma distribuição Exponencial. Na prática, a probabilidade de uma nova chegada não depende de quando foi a última.
- Segundo M: Significa que os tempos de atendimento também seguem uma distribuição exponencial.
- 1: Significa que existe apenas um servidor.
Parâmetros fundamentais
O modelo M/M/1 é definido por apenas dois parâmetros: λ que indica o número médio de requisições por unidade de tempo e μ que indica o número médio de requisições atendidas por unidade de tempo. A partir desses dois parâmetros deriva-se o parâmetro mais importante desse sistema.
$$ \rho = \frac{\lambda}{\mu} $$
ρ é chamado de intensidade de tráfego ou fator de utilização. Ele representa a fração do tempo em que o servidor está ocupado. A intensidade de tráfego nos diz algo muito importante, o servidor só está estável se ρ < 1. Quando λ ≥ μ, o servidor entra em colapso e a fila de requisições tende ao infinito.
Certifique-se sempre de que λ e μ estejam na mesma unidade de tempo. Se você medir a chegada em requisições por segundo, a taxa de serviço também deve ser calculada em requisições por segundo.
Métricas do servidor
Com o ρ calculado, toda a dinâmica do servidor pode ser derivada analiticamente. Abaixo é listado várias informações que podemos pegar a partir de ρ.
Número médio de requisições no servidor
Quantidade média de requisições no servidor, isto é, em espera + sendo atendidas.
$$ L = \frac{\rho}{1 – \rho} $$
Número médio de requisições na fila
Quantidade média de requisições aguardando na fila para serem processadas pelo servidor.
$$ L_q = \frac{\rho^2}{1 – \rho} $$
Tempo médio
Podemos calcular o tempo médio em dois momentos diferentes. O primeiro momento é quando a requisição entra no servidor, então é computabilizado o tempo de espera e o tempo de processamento. Chamamos isso de tempo médio no servidor o qual é dado pela fórmula abaixo.
$$ W = \frac{1}{\mu – \lambda} $$
O segundo momento que podemos calcular o tempo médio é durante a espera na fila de requisições para serem atendidas. Sua fórmula é apresentada abaixo.
$$ W_q = \frac{\lambda}{\mu(\mu – \lambda)} $$
Note que, essas serão as únicas informações que não dependem necessariamente de ρ.
Probabilidade do servidor não estar processando nada
Para calcular a probabilidade de não haver nenhuma requisição no servidor usamos:
$$ P_0 = 1 – \rho $$
Probabilidade de haver N requisições
Essa fórmula calcula a probabilidade de haver n requisições no servidor, seja em espera ou sendo processado por ele. Lembre-se que n é a quantidade de requisições.
$$ P_n = (1 – \rho) \cdot \rho^n $$
Probabilidade de haver mais de n requisições
Essa função é muito útil quando queremos estimar a probabilidade da fila ultrapassar um determinado tamanho.
$$ P(N>n) = \rho^{n+1} $$
Implementando as métricas usando Python
Agora vamos implementar cada métrica como uma função independente, documentada e explicada em detalhes. Essa abordagem facilita o entendimento de cada cálculo individualmente e torna o código mais didático.
O código será implementado na ferramenta Google Colab, então para iniciarmos, acesse a plataforma e clique em “Novo Notebook”. A tela que aparecerá é semelhante a da imagem abaixo.
Se você chegou nessa tela, então o próximo passo é a implementação das funções que calculam as métricas que vimos acima.
Verificando a estabilidade do servidor
Antes de qualquer cálculo, precisamos garantir que o sistema é estável. Como vimos, isso só é verdade quando ρ < 1. Todas as funções a seguir dependem dessa condição.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
def calcular_utilizacao(lamb: float, mu: float):
if lamb <= 0 or mu <= 0:
raise ValueError("λ e μ devem ser valores positivos.")
rho = lamb / mu
if rho >= 1:
print(f"SISTEMA INSTÁVEL: ρ = {rho:.4f}. A fila cresce sem limite.")
else:
print(f"Sistema estável: ρ = {rho:.4f} ({rho * 100:.2f}% de utilização)")
return rho
Calculando a média de requisições no servidor
def calcular_L(rho: float):
if rho >= 1:
return float('inf')
return rho / (1 - rho)
Calculando o número médio de requisições na fila
def calcular_Lq(rho: float):
if rho >= 1:
return float('inf')
return (rho ** 2) / (1 - rho)
Calculando o tempo médio no servidor
def calcular_W(lamb: float, mu: float):
if lamb >= mu:
return float('inf')
return 1 / (mu - lamb)
Calculando o tempo médio na fila
def calcular_Wq(lamb: float, mu: float):
if lamb >= mu:
return float('inf')
return lamb / (mu * (mu - lamb))
Probabilidade do servidor estar vazio
def calcular_P0(rho: float):
if rho >= 1:
return 0.0
return 1 - rho
Probabilidade de exatamente N requisições no servidor
def calcular_Pn(rho: float, n: int):
if n < 0:
raise ValueError("n deve ser um inteiro não-negativo.")
if rho >= 1:
return 0.0
return (1 - rho) * (rho ** n)
Probabilidade de mais de N requisições no servidor
def calcular_prob_maior_que_n(rho: float, n: int):
if n < 0:
raise ValueError("n deve ser um inteiro não-negativo.")
if rho >= 1:
return 1.0
return rho ** (n + 1)
Indicadores de dimensionamento e performance
Até aqui, todas as métricas que calculamos respondem perguntas sobre o estado médio do sistema. São médias, e médias escondem variação. Um W de 50ms não significa que toda requisição responde em 50ms, algumas respondem em 10ms, outras em 200ms.
É exatamente aí que as funções a seguir entram. Elas transformam os valores calculados anteriormente em respostas práticas e operacionais, indo além da média para responder perguntas como:
- Qual é o pior caso que 99% dos usuários enfrentam?
- A partir de qual carga meu servidor se torna arriscado?
- O que acontece com todas as métricas se a carga subir 20% amanhã?
Cada função abaixo consome os resultados das funções anteriores e os transforma em inteligência aplicada.
Percentil do tempo no sistema
O tempo que uma requisição passa no servidor em uma fila M/M/1 segue uma distribuição exponencial com taxa (μ – λ). Isso não é coincidência, é uma consequência direta do tempo de processamento e os intervalos de chegada também serem exponenciais. A média dessa distribuição é exatamente 1/(μ – λ), que é o nosso W. Ou seja, o percentil de tempo e W descrevem a mesma distribuição: W é sua média, e o percentil é um ponto específico de sua cauda. Sabendo disso, dizemos que o tempo no servidor segue uma distribuição exponencial cuja sua função de distribuição acumulada é apresentada logo abaixo.
$$ F(t) = P(T ≤ t) = 1 – e^{-(μ-λ)\cdot t} $$
Como queremos calcular o tempo em função de ρ, precisamos manipular a equação para isolar o t, assim teremos:
$$ t = -\ln\frac{(1 – p)}{(μ – λ)} $$
Traduzindo essa equação para um código em Python temos
def calcular_percentil_tempo(lamb: float, mu: float, percentil: float):
if not (0 < percentil < 1):
raise ValueError("Percentil deve estar entre 0 e 1 (ex: 0.95).")
if lamb >= mu:
return float('inf')
taxa_saida = mu - lamb
return -np.log(1 - percentil) / taxa_saida
Mas por que isso é importante ? Porque são usados para encontrar o melhor desempenho do servidor. Saber que W = 50ms é insuficiente para garantir ao cliente que “99% das requisições respondem em até 200ms”. Esta função transforma W em uma família de garantias concretas: P50, P90, P95, P99.
Capacidade máxima recomendada
Sabemos pela análise de L e Lq que o comportamento do sistema é altamente não-linear próximo de ρ = 1: um aumento de 10% na carga pode dobrar a fila. Mas onde exatamente fica o limite seguro de operação?
Esta função inverte a lógica de calcular_utilizacao. Em vez de calcular ρ a partir de λ e μ, ela parte de um ρ máximo aceitável e devolve o λ máximo correspondente. É a ponte entre a análise matemática e uma regra operacional concreta: “nunca deixe λ ultrapassar este valor”.
def calcular_capacidade_maxima(mu: float, margem: float):
if not (0 < margem < 1):
raise ValueError("A margem deve estar entre 0 e 1.")
return mu * margem
Isso é importante porque transforma a análise em uma ação concreta. Após calcular ρ, L, Lq e o percentis, o engenheiro precisa saber: "a partir de qual número eu devo escalar?". Esta função responde isso diretamente.
Análise de sensibilidade
Todas as funções anteriores analisam o sistema em um ponto fixo: λ = 80, μ = 100. Mas sistemas reais têm tráfego variável. O que acontece nas métricas se λ aumentar 10% numa Black Friday? E se cair 30% de madrugada?
Esta função responde isso sistematicamente. Ela reutiliza internamente toda a cadeia de cálculo, isto é, ρ, L, Lq, W, Wq para múltiplos valores de λ, gerando uma tabela comparativa. É como chamar as cinco primeiras funções em loop, para cada cenário possível.
def calcular_sensibilidade(
lamb: float,
mu: float,
variacoes: list = [-0.30, -0.20, -0.10, 0, 0.10, 0.20, 0.30]
):
resultados = []
for v in variacoes:
lamb_novo = lamb * (1 + v)
rho_novo = lamb_novo / mu
estavel = rho_novo < 1
if estavel:
L = rho_novo / (1 - rho_novo)
Lq = (rho_novo ** 2) / (1 - rho_novo)
W = 1 / (mu - lamb_novo)
Wq = lamb_novo / (mu * (mu - lamb_novo))
else:
L = Lq = W = Wq = float('inf')
resultados.append({
"Variação λ": f"{v*100:+.0f}%",
"λ": round(lamb_novo, 2),
"ρ": f"{rho_novo*100:.1f}%",
"Estável": "SIM" if estavel else "NAO",
"L": round(L, 2) if estavel else "∞",
"Lq": round(Lq, 2) if estavel else "∞",
"W (s)": round(W, 5) if estavel else "∞",
"Wq (s)": round(Wq, 5) if estavel else "∞",
})
return pd.DataFrame(resultados)
Quando estamos medindo as métricas de um servidor, devemos ser capaz de questionar "e se?". Esta função entrega o planejamento de capacidade: uma tabela que podemos consultar antes de um momento de estresse do servidor ou antes de um evento de alto tráfego. Ela também torna visível o ponto exato de colapso do sistema.
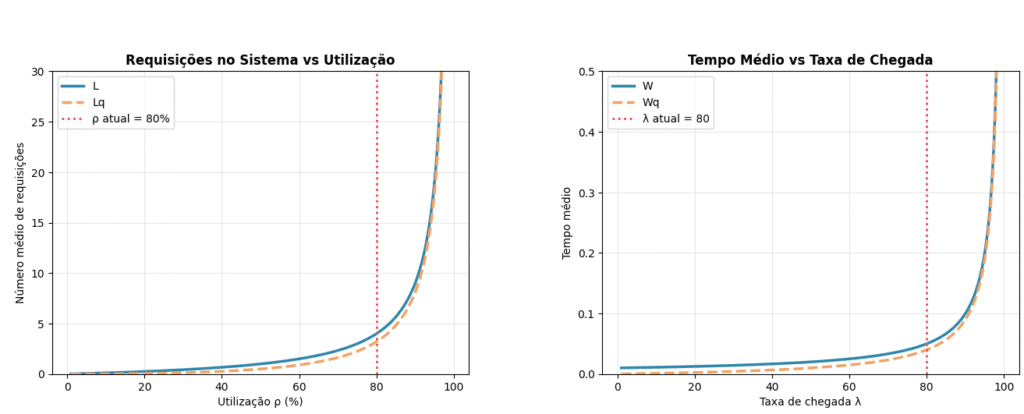
Criando um dashboard visual
Temos agora um conjunto rico de métricas numéricas. O problema é que números em tabela são difíceis de apresentar para usuários e de usar para comunicar risco de forma imediata. O dashboard resolve isso: ele traduz todas as métricas anteriores em gráficos, tornando os padrões e riscos visualmente óbvios. O dashboard implementará quatro gráficos:
- Mostra qual estado mais provável que o servidor se encontra
- Mostra o risco da fila longa
- Expõe e não-linearidade da chegada de requisições no servidor
- Mostra onde a latência explode
def plotar_dashboard(lamb: float, mu: float, rho: float, n_max: int = 20):
L = rho / (1 - rho)
W = 1 / (mu - lamb)
ns = np.arange(0, n_max + 1)
lamb_range = np.linspace(0.01 * mu, 0.99 * mu, 300)
rho_range = lamb_range / mu
cor_azul = "#2E86AB"
cor_laranja = "#F4A261"
cor_vermelho = "#E84855"
fig = plt.figure(figsize=(16, 12))
fig.suptitle(
f"Dashboard — Fila M/M/1 | λ={lamb}, μ={mu}, ρ={rho:.0%}",
fontsize=14, fontweight="bold", y=0.98
)
gs = gridspec.GridSpec(2, 2, figure=fig, hspace=0.38, wspace=0.32)
ax1 = fig.add_subplot(gs[0, 0])
probs = [(1 - rho) * (rho ** n) for n in ns]
ax1.bar(ns, probs, color=cor_azul, alpha=0.8, edgecolor="white")
ax1.axvline(L, color=cor_vermelho, linestyle="--",
linewidth=2, label=f"L = {L:.2f}")
ax1.set_title("Distribuição P(N = n)", fontweight="bold")
ax1.set_xlabel("Requisições no sistema (n)")
ax1.set_ylabel("Probabilidade")
ax1.legend()
ax1.grid(axis="y", alpha=0.3)
ax2 = fig.add_subplot(gs[0, 1])
probs_gt = [rho ** (n + 1) for n in ns]
ax2.plot(ns, probs_gt, color=cor_laranja, linewidth=2.5,
marker="o", markersize=5, label="P(N > n)")
ax2.axhline(0.05, color=cor_vermelho, linestyle="--",
linewidth=1.5, label="Risco de 5%")
ax2.set_title("Probabilidade Acumulada P(N > n)", fontweight="bold")
ax2.set_xlabel("Requisições no sistema (n)")
ax2.set_ylabel("P(N > n)")
ax2.legend()
ax2.grid(alpha=0.3)
ax3 = fig.add_subplot(gs[1, 0])
Ls = rho_range / (1 - rho_range)
Lqs = (rho_range ** 2) / (1 - rho_range)
ax3.plot(rho_range * 100, Ls, color=cor_azul, linewidth=2.5, label="L")
ax3.plot(rho_range * 100, Lqs, color=cor_laranja, linewidth=2.5,
linestyle="--", label="Lq")
ax3.axvline(rho * 100, color=cor_vermelho, linestyle=":",
linewidth=2, label=f"ρ atual = {rho:.0%}")
ax3.set_title("Requisições no Sistema vs Utilização", fontweight="bold")
ax3.set_xlabel("Utilização ρ (%)")
ax3.set_ylabel("Número médio de requisições")
ax3.set_ylim(0, min(30, Ls.max() * 1.1))
ax3.legend()
ax3.grid(alpha=0.3)
ax4 = fig.add_subplot(gs[1, 1])
Ws = 1 / (mu - lamb_range)
Wqs = lamb_range / (mu * (mu - lamb_range))
ax4.plot(lamb_range, Ws, color=cor_azul, linewidth=2.5, label="W")
ax4.plot(lamb_range, Wqs, color=cor_laranja, linewidth=2.5,
linestyle="--", label="Wq")
ax4.axvline(lamb, color=cor_vermelho, linestyle=":",
linewidth=2, label=f"λ atual = {lamb}")
ax4.set_title("Tempo Médio vs Taxa de Chegada", fontweight="bold")
ax4.set_xlabel("Taxa de chegada λ")
ax4.set_ylabel("Tempo médio")
ax4.set_ylim(0, W * 10)
ax4.legend()
ax4.grid(alpha=0.3)
plt.show()
Como tudo se encaixa na main
Antes de ver o código, é importante entender a ordem lógica das chamadas e por que cada uma depende das anteriores. Cada camada só faz sentido porque a anterior foi executada. Você não calcula percentis sem ter entendido W. Você não faz análise de sensibilidade sem ter visto o estado atual. E você não plota o dashboard sem ter todos os valores calculados.
#...Funções já implementadas
def main():
LAMB = 80
MU = 100
print("ANÁLISE COMPLETA DE FILA M/M/1 — SERVIDOR WEB")
rho = calcular_utilizacao(LAMB, MU)
L = calcular_L(rho)
Lq = calcular_Lq(rho)
print(f"\nRequisições no sistema (L) : {L:.4f}")
print(f"Requisições na fila (Lq): {Lq:.4f}")
print(f"(diferença L - Lq = {L - Lq:.4f} ≈ ρ = {rho:.4f})")
W = calcular_W(LAMB, MU)
Wq = calcular_Wq(LAMB, MU)
print(f"\nTempo no sistema (W) : {W:.4f}s ({W*1000:.1f}ms)")
print(f"Tempo na fila (Wq): {Wq:.4f}s ({Wq*1000:.1f}ms)")
print(f"Verificação Lei de Little: λ×W = {LAMB*W:.4f} ≈ L = {L:.4f}")
P0 = calcular_P0(rho)
print(f"\nP(sistema vazio) (P0): {P0:.4f} ({P0*100:.1f}% do tempo ocioso)")
print(f"\nDistribuição de probabilidade — primeiros 8 estados:")
print(f" {'n':>3} | {'P(N=n)':>10} | {'P(N>n)':>10}")
print(f" {'-'*3}-+-{'-'*10}-+-{'-'*10}")
for n in range(8):
pn = calcular_Pn(rho, n)
pgt = calcular_prob_maior_que_n(rho, n)
print(f" {n:>3} | {pn:>10.6f} | {pgt:>10.6f}")
n_alerta = 10
risco = calcular_prob_maior_que_n(rho, n_alerta)
print(f"\nRisco operacional:")
print(f" P(N > {n_alerta}) = {risco:.4f} ({risco*100:.2f}%)")
print(f" Ou seja: {risco*100:.1f}% do tempo há mais de {n_alerta} "f"requisições acumuladas.")
print(f"\nPercentis de latência (SLA):")
for p, nome in [(0.50, "P50"), (0.90, "P90"),
(0.95, "P95"), (0.99, "P99")]:
t = calcular_percentil_tempo(LAMB, MU, p)
print(f" {nome}: {t*1000:.1f}ms")
cap_80 = calcular_capacidade_maxima(MU, margem=0.80)
cap_70 = calcular_capacidade_maxima(MU, margem=0.70)
print(f"\nCapacidade recomendada:")
print(f"Teto em 80% de utilização: {cap_80:.1f} req/s")
print(f"Teto em 70% de utilização: {cap_70:.1f} req/s")
print(f"λ atual: {LAMB} req/s → margem disponível (80%): "
f"{cap_80 - LAMB:.1f} req/s")
print(f"\nAnálise de sensibilidade — cenários de carga:")
df = calcular_sensibilidade(LAMB, MU)
print(df.to_string(index=False))
print(f"\nObserve: +10% em λ dobra Lq (de 3.2 para 6.4).")
print(f"Com +20%, Lq vai para 23. Com +30%, colapso")
print(f"\n Gerando dashboard visual...")
plotar_dashboard(LAMB, MU, rho, n_max=25)
if __name__ == "__main__":
main()
Você pode pegar esse código completo no meu GitHub. Acessa lá!
Resultado da execução
Após executar todo o código, podemos notar várias informações acerca do servidor que possui os parâmetros λ e μ.
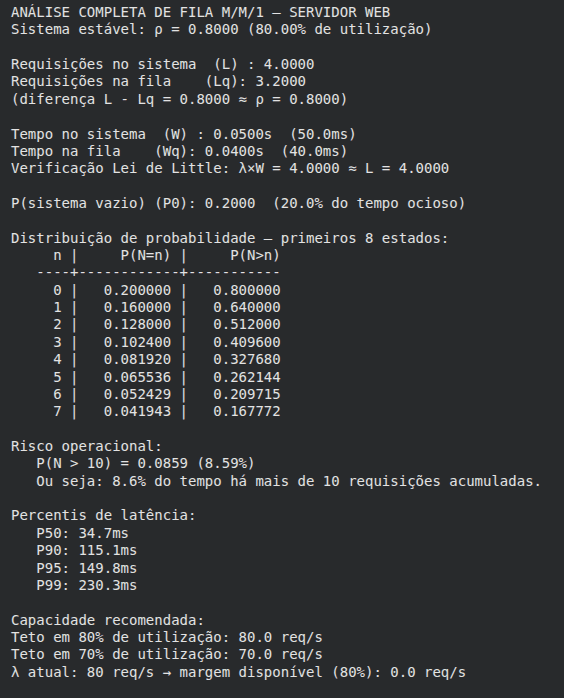
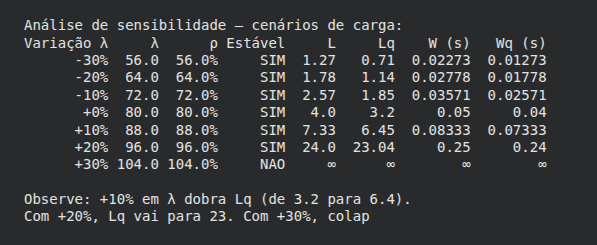
Por fim, abaixo é apresentado o dashboard visual que nos auxilia a ter uma visão mais ampla de todo os números apresentados até aqui.
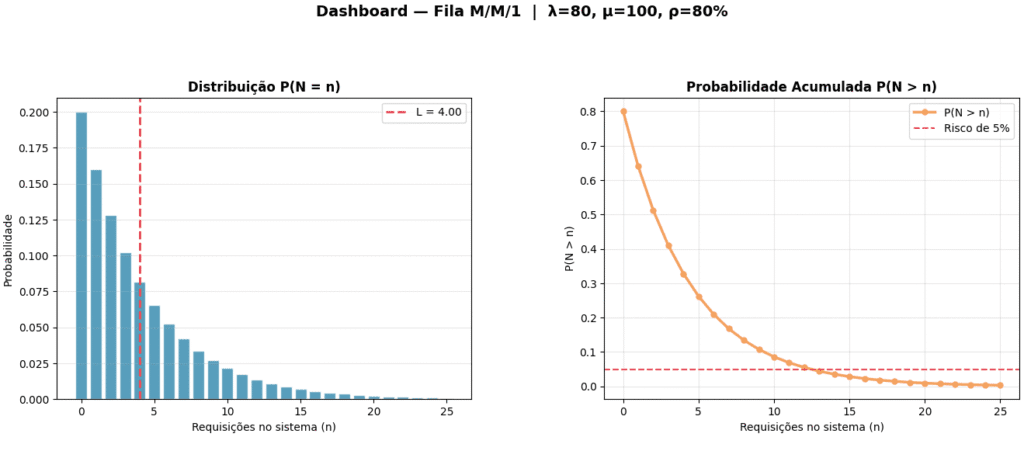
Curtiu mas ainda não tem um servidor web ? Crie um servidor construindo seu próprio load balancer faça o teste !


